Be CAS I told you not to! More CAS pain points with CM12
Well I told you not to install a CAS, didn’t I? But of course I no choice since my team supports the servers that manage 365K clients. Well, we had one heck of a week last month.
It started with a phone call from Sherry Kissinger waking me up to say we had a replication issue. She said she dropped a pub file to get the Hardware_Inventory_7 replication group to sync. My 1st thought was that our Alabama primary site was holding onto files again with SEP (Symantec Endpoint Protection) not honoring exclusions. We had files stuck in despoolr.box the prior week and entries in the statesys.log showing that it was having problems trying to open files. I told her to uninstall SEP and I’d go into my office and logon.
So I logged on and start looking around. Our CM12 R2 environment consists of a CAS & 3 primary sites. The monitoring node in the console was showing all sorts of site data replication groups in degraded status. That’s because the CAS was in maintenance mode and not active (easily seen with exec spDiagDrs). Primary sites hold on to their site data until they see the CAS active.
By the way, if you own a CAS and run into DRS issues, you’ll become well acquainted with spDiagDRS. It’s a harmless query you can run right now to look at how your DRS is doing.
What Sherry was seeing there was normal. It would look that way until the primary site caught up with Hardware_Inventory_7. But that was only the beginning of the story.
When you run RLA on a primary against site data (or drop a pub file as a last resort) what happens is the primary dumps all the tables in that replication group into bcp files and compresses them into a cab file in the rcm.box. It copies that cab file up via the sender to the despoolr.box\receive folder on the CAS, which decompresses it back to a folder in the rcm.box on the CAS. Then RCM takes over and parses each bcp file by grabbing 5000 rows at a time and merges them into its table in the CM database.
RCM = Replication Configuration Manager
RCM activity can be viewed in the rcmctrl.log and viewing that on the Alabama primary showed that it failed with “an internal SQL error”. Huh? The SQL logs were clear. A colleague noticed that the D drive on the primary site was full. With a database as large as ours, the 100GB we gave for the CM12 folders and inboxes, wasn’t enough for the 120GB of data for that one replication group.
We quickly got another 200GB of SAN added to those D drives and another 600GB added to the CAS’s D drive (so that it could fit up to 200GB of data per site should all 3 sites need to send up recovery files at once).
Then we restarted the RCM thread on the primary site and this time it had the room to finish. But it took forever to compress that data into a cab file to send to the CAS and it took a long time for the CAS to decompress it. Then RCM does this excruciatingly slow slicing of 5000 rows at a time merge into its database. That took all night to run. I assume it does few tables at a time because if you were doing a restore for a CAS, all client data tables would be sent up at once).
But the story gets worse.
After all night of working on this we hit an error stopping the entire process.
Error: Failed to BCP in.
Error: Exception message: ['ALTER TABLE SWITCH' statement failed. The table 'CM_CAS.dbo.INSTALLED_SOFTWARE_DATA' is partitioned while index '_sde_ARPDisplayName' is not partitioned.]
Error: Failed to apply BCP for all articles in publication Hardware_Inventory_7.
Will try to apply BCP files again on next run
What the deuce? Well that one was our fault for making our own index. Quick fix: remove the index. OK. GO! C’mon, do something! But nothing happened. We waited for an hour and it was clear that it was just not going to start again. So we ran RLA and started all over again.
All of this takes time so what I’m describing is now the 3rd day with site data down (inventory, status messages, etc.). We told all the admins that their data could be seen on the primary sites and that work would go out as normal, but all the nice SRS reports we got them used to using were rather useless because the CAS had stale data.
The next attempt of the group got the first table of the replica group done but blew up on the second for the same reason as before. Yes, we forgot to go look at other indexing our team might have done. Oops; so we disabled all the rest. But now what? There is no way we could let this go for another 8 hours to do this one replica group again.
We kept running ideas past our PFEs but they had nothing helpful. I don’t blame them because few people know DRS well. Last year, after a 3-week CSS ticket, we gave up on our lab and rebuilt it after Microsoft couldn’t fix it.
So how could we kick-start RCM to pick up where it left off instead of starting all over? It had already consumed a 78GB table of the bcp files. It was just unbearable to consider starting over. So we rolled up our sleeves and came up with this:
- update RCM_DrsInitializationTracking set TryCount=0 where InitializationStatus=99
- update RCM_DrsInitializationTracking set InitializationStatus=5 where InitializationStatus=99
- In the root of rcm.box, create a file which has the exact name of the bcp folder inside the rcm.box folder and a file extension of .init
The failed group had gone to a 99 in Initialization Status (simply run select * fromRCM_DrsInitializationTrackingto see all replication groups) and it had a TryCount of 3 on it. After 3 tries, it just stops trying.
![]()
Setting TryCount to 0 did nothing. Setting Initialization Status to 5 still didn’t kick it. But adding the init file (and yes, it has to be all 3 tasks) finally got RCM to look at the folder and pick up where it left off.
Then what? Well once that was done, the CAS told all the primary sites that their data was stale. Now I would like to think that they would already know what they sent before and just send up the deltas, but nooooooo! What the CAS does next is to drop the tables of each replica group into bcp files and send them down to the primary sites. Why? I assume that this must be used for them to compare and then send up the deltas.
Looking at how long that was going to take got depressing fast. The CAS is a 1.5TB database and the primary sites are 600GB. We’re talking about a lot of data even when it’s delta. Is there such a thing as “too big for DRS?” Because I think we fit the bill. We simply were not going to catch up.
So I proposed we go with the nuclear option: Distributed Views.
What is that and why do it?
Distributed Views is where you tell your primary site to hold onto client data locally and not send it to the CAS. Navigate to Monitoring\Database Replication\Link Properties and you’ll see you get 3 boxes of groups which you can decide to just leave on the primary site. We chose the Hardware Inventory box because that was really the site data not replicating. So we figured, leave it on the primary and hope the WAN links hold up when running SRS reports or anything in the console that has to go look at client data.
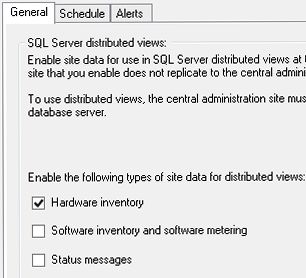
We did this for the Alabama site to start with. After the other primary sites showed that they still were not recovering, we enabled distributed views on them too, one at a time. 90 minutes after enabling distributed views, all of our links were finally showing successful status again.
How does this affect SRS reports if the data isn’t on the CAS? Well under the covers, SRS has to go to each site to run the query if the view contains client related data. That can put load on your primary sites, but less load than all that site replication I would think. And we had actually had this enabled on the Minneapolis site that is next to the CAS at one time. We disabled it only because we found some issues and were concerned that it wasn’t ready to use yet (see Sherry’s blog for one issue).
The downside of trying distributed views is that there simply isn't going to be an easy way to turn it back off. Once you undo it, your primary is going to have to send all of that data to the CAS. And for large sites, this is very painful if not impossible. If we ever get the confidence to disable distributed views I think we’d have to disable hinv, disable DV, enable hinv and let all that data come back as full per client schedules. To put into perspective how much inventory that is that would have to replicate up: our CAS database is now 1TB smaller.
I said “if we ever get the confidence” to go back to sending all data up, we might do it, but we don’t have confidence right now. Why?
First off that slicing of the bcp file seems to be hard coded at 5000 rows at a time. For tables that are millions of rows in size, the wait is agonizing and just not palatable. Should we ever have to reinitialize a replication group, we simply cannot afford a day or days of waiting. We’ve asked our PFEs to see if there is some hidden switch to overcome that 5000 row number and if there isn’t one, we’ll submit a DCR. This really needs to be addressed for very large sites. We need to throttle (my servers could probably consume 50K rows at a time). And RCM isn't multithreaded. Crazy.
As for why DRS had ever failed in the first place, well it didn’t. It was degraded and we should have tried to let that one catch up. You have to know which tables you’re messing with for both RLA and pub files. Here is a query to help you know what is where:
SELECTRep.ReplicationGroup,
Rep.ReplicationPattern,
App.ArticleName,App.ReplicationID
FROMvArticleDataASApp
INNERJOINv_ReplicationDataASRepONApp.ReplicationID=Rep.ID
And you can combine that with:
execspDiagGetSpaceUsed
Those queries should help you make an educated decision on dropping pub files on huge sites. Generally running RLA is safer, but you should still look at the data to see what's going on.
- Created on .